Generating a SQLite word dictionary (with definitions) from WordNet using Python
I recently needed a SQLite dictionary with word, type, and definition(s). Turns out, it was easy enough to make my own!
All code in this article is available in a WordNetToSQLite repo, as is the final words.db database (license).
Objective
For an upcoming word game app, I needed a dictionary of words. I wanted to know the type of word (noun / verb / adjective / adverb), and a definition for each. Plus, it should only include sensible words (e.g. no proper nouns, acronyms, or profanity).
I decided to prefill a SQLite database and ship it with my app, since I can easily update it by just shipping a new database (or even remotely with SQL!). Android also has good support for retrieving the data from SQLite.
However, finding a suitable list of words was tricky! I found plenty of sources containing just words, or with no information on source or licensing. Eventually, I discovered Princeton University’s WordNet exists, and luckily it’s free to use and has a very liberal license. There’s also a more up to date fork (2024 instead of 2006).
However, it contains a lot of unneeded information and complexity, and is 33MB+ uncompressed. Time to get filtering…
Running script
If you wish to recreate words.db from scratch, or customise the results, you can:
- Obtain a WordNet format database.
- I used a regularly updated fork (2024 edition, WNDB format)
- You can also use the original WordNet files from 2006 (
WNdb-3.0.tar.gzfrom WordNet)
- Extract your download, and place the
data.xfiles in/wordnet-data/. - Run
py wordnet-to-sqlite.py. - In a minute, you’ll have a word database!
Out of the box, the script takes ~60 seconds to run. This slightly slow speed is an intentional trade-off in exchange for having full control over the language filter (see profanity removal).
Notes on results
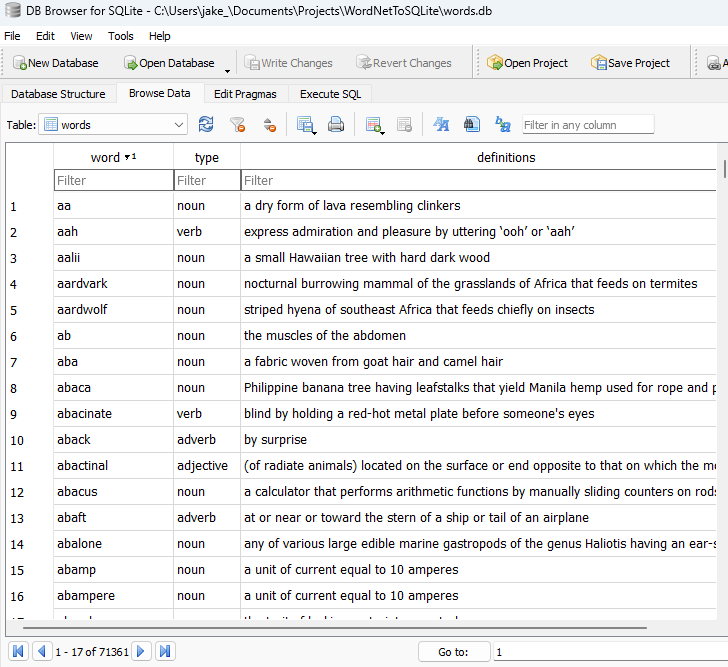
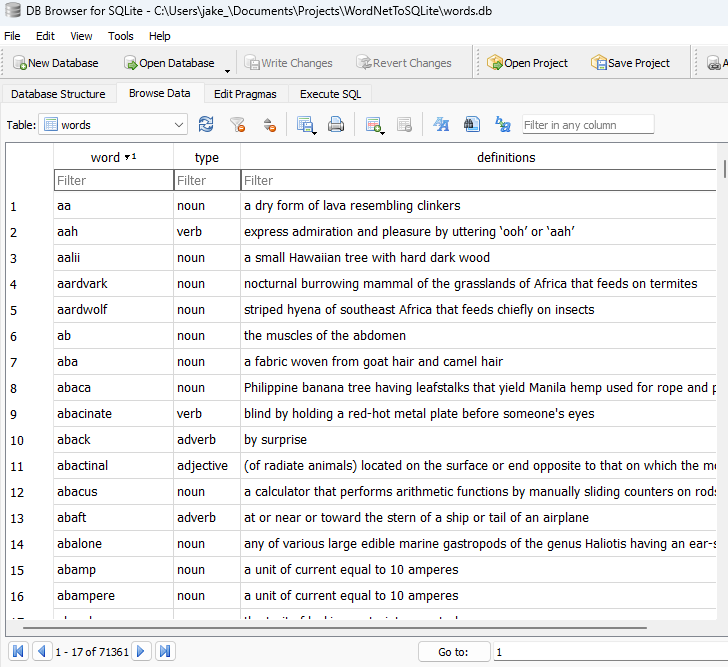
The database contains over 71k word & word type combinations, each with a definition. I use the open source DB Browser for SQLite to browse the results, looking something like this:
Schema definition
Only one definition per word for the same type is used (e.g. with the noun article, but not the verb):
word:- Any words with uppercase letters (e.g. proper nouns) are removed.
- Any 1 character words are removed.
- Any words with numbers are removed.
- Any words with other characters (apostrophes, spaces) are removed.
- Most profane words (626) are removed.
- Roman numerals are removed (e.g.
XVII).
type:- Always
adjective/adverb/noun/verb.
- Always
definition:- Definition of the word, uses the first definition found.
- Most profane definitions (1124) are replaced with empty space.
- May contain bracketed usage information, e.g.
(dated). - May contain special characters like
',$,!,<,[, etc.
Notes on code
Whilst wordnet-to-sqlite.py is under 100 lines of not-very-good Python and doesn’t do anything too crazy, I’ll briefly walk through how it works.
Raw data
The raw data in WordNet databases looks like this (unknown is the only valid noun to extract, with a single definition):
08632096 15 n 03 unknown 0 unknown_region 0 terra_incognita 0 001 @ 08630985 n 0000 | an unknown and unexplored region; "they came like angels out the unknown"
Further notes on WordNet’s data files are here, this Python script just does a “dumb” parse then filters out numerical data and invalid words (spaces, capitalised letters, Roman numerals etc).
Process
- For each word type file (
data.noun,data.adj, etc), pass it toparse_file. - Loop through every line in this file, primarily using
split/rangeto fetch as many words as are defined, without taking the0and other non-word data. - Check each of these words is “valid”, specifically that it’s lowercase letters only (no symbols / spaces), isn’t a Roman numeral (by matching the word & description), and isn’t a profane word.
- If the word is valid, add it to the dictionary so long as it isn’t already defined for the current word type. For example, a word might be used as a noun and an adjective.
- Finally, output all these word, type, and definition rows into a SQLite database we prepared earlier.
Luckily, as Python is a very readable language, function definitions almost read like sentences:
def is_valid_word(word, definition):
return (
word.islower() and
word.isalpha() and
len(word) > 1 and
not is_roman_numeral(word, definition) and
not is_profanity(word)
)
Profanity removal
Since this dictionary is for a child-friendly game, profane words should be removed if possible. Players are spelling the words themselves, so I don’t need to filter too aggressively, but slurs should never be possible.
The eventual solution is in /profanity/, where wordlist.json is the words to remove, manually-removed.txt & manually-added.txt are the words I’ve manually removed from / added to the wordlist, and log.txt is every removed word & definition.
Choice of package
I tried out quite a few Python packages for filtering out the profane words, with pretty poor results overall. They were generally far too simple, required building a whole AI model, were intended for machine learning tasks, or seemed entirely abandoned / non-functional.
Eventually, I used better_profanity 0.6.1 for filtering (0.7.0 has performance issues), and whilst it was fast, it missed very obvious explicit words, whilst triggering hundreds of false positives. However, this was the best package so far despite being semi-abandoned, so I used it for most of the project (before rolling my own).
Word list
With a 4 year old wordlist, missing quite common slurs wasn’t too surprising. As such, I tried using a much more comprehensive wordlist (2823 words vs better profanity’s 835). At this point, the library’s “fuzzy” matching was far too fuzzy, and half the words had their definitions removed!
After logging all the removed words and definitions, I also noticed this list was quite over-zealous. I ended up manually removing 123 words (see whitelisted.txt), since words like “illegal”, “kicking”, “commie” are absolutely fine to all but the most prudish people. Removing false positives took the total number of profane removals from 3,368 to 1,750, all of which seem sensible.
Whilst I now had a good word list, at this point I gave up using libraries, and decided to just solve it myself. It’s fine if the solution is slow and inefficient, so long as the output is correct.
Using regexes
I implemented a solution that just checks every word (& word of definition) against a combined regex of every profane word. Yes, this is a bit slow and naive, but it finally gives correct results!
with open(wordlist_path, 'r', encoding='utf-8') as f:
profane_words = set(json.load(f))
combined_profanity_regex = re.compile(r'\b(?:' + '|'.join(re.escape(word) for word in profane_words) + r')\b', re.IGNORECASE)
The script takes about a minute to parse the 161,705 word candidates, pull out 71,361 acceptable words, and store them in the database. Fast enough for a rarely run task.
Optimisation
A few steps are taken to improve performance:
executemanyis used to insert all the database rows at once.- A combined (very long) regex is used since it’s far faster than checking a word against 2700 regexes.
- A
setis used for the word list, so words can be quickly checked against it. - Only one definition for each word & type is included, as this reduces the database size from 7.2MB to 5.1MB.
Conclusion
The approach taken to generate the database had quite a lot of trial and error. Multiple times I thought I was “done”, then I’d check the database or raw data and discover I was incorrectly including or excluding data!
SQLite Browser was extremely useful during this process, as the near-instant filtering helped me check profane words weren’t slipping through. It also helped me catch a few times when technical data would leak into the definitions.
I’ll absolutely tweak this script a bit as I go forward (I’ve implemented all my initial ideas since starting the article!) and my requirements change, but it’s good enough for a starting point. Specifically, next steps are probably:
Try the WordNet 3.1 database instead of 3.0, and see if there’s any noticeable differences (there’s no release notes!)Tried, not much changeUse an open source fork, since it has yearly updates so should be higher quality than WordNet’s 2006 data.Done!Replace the current profanity library, since it takes far longer than the rest of the process, and pointlessly checks letter replacements (e.g.Done!h3ll0) despite knowing my words are all lowercase letters.Use the word + type combo as a composite primary key on the database, and ensure querying it is as efficient as possible.Done! Increased database size by ~20%, so will see if it’s necessary.