Building a GitHub Actions script to fetch metadata from multiple YouTube channels, and save it into a Markdown file
I recently created a list of Jerma fan channels, and have now added automatically updating channel statistics! This requires interacting with YouTube’s API, parsing JSON, writing Markdown, merging files and more, so here’s a full guide to building something similar.
Note: A super-summarised version of this post (without any explanations) appeared on Code Review Stack Exchange. Additionally, the site was previously at jerma.jakelee.co.uk before moving to channels.jerma.io.
Objective
So, what am I trying to create? Ultimately, a way to convert a list of YouTube channels into a Markdown file with channel statistics, and I want this list to update both on demand and on a schedule.
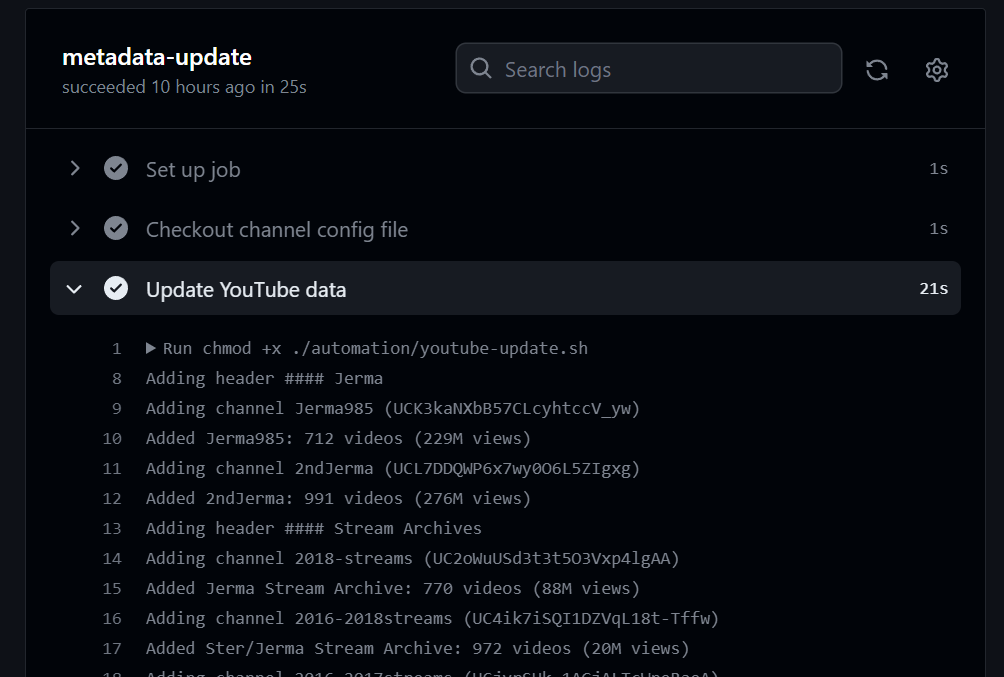
Before I dive into the technical details, here’s all the code in case you want to skip the words:
And some relevant inputs / outputs:
Prep work
I’m going to use GitHub Actions for my script, and perform this series of steps:
- Pull down the repo.
- Update YouTube channel stats:
- Parse a list of YouTube channel IDs and nicknames.
- Fetch their metadata via YouTube’s Channel API.
- Build up Markdown tables using this metadata.
- Load a Markdown template, and replace a placeholder with the generated Markdown.
- Save these changes.
Before we build our script however, we need to generate an API key, and have the ability to actually run the script on GitHub Actions!
Accessing YouTube API
YouTube’s official API guide1 is a great resource, and I’ll just be providing more specific steps here.
- Open Google Developer Console2 and create a new project.
- With this project selected, go to Credentials3 and
Create Credentials->API key. - Go to the API Library4, search
YouTube Data API v35, and clickEnable. - Once created, click
Edit API key(on Credentials screen)- Give it a sensible name.
- Set an API restriction to
YouTube Data API v3.

That’s it! You now have an API key that is relatively safe (as it can only be used for YouTube), ready to store securely in GitHub and fetch YouTube data with.
It’s worth pointing out that Google recommends6 restricting who can use this API key. Unfortunately GitHub Actions uses thousands of (occasionally changing) IP addresses7, so whitelisting them all is not viable!
Preparing GitHub Action
I won’t go through the basics of making a GitHub repo (although GitHub has a guide8), and will assume it already exists.
Adding GitHub secret
We’re going to add our new API key as a GitHub Action secret, so that the CI can access it without it being in plaintext. Under your repo’s Settings, navigate to Security -> Secrets and variables -> Actions, then New repository secret.
Give your secret a simple name (e.g. API_KEY), put the key itself under Secret, and add it.

Basic workflow setup
Next, we need to make a workflow9 to actually trigger our upcoming code.
To do this, create a YAML config file inside .github/workflows/ called something intuitive like metadata-update.yml. Here is mine.
Before adding any steps, we need some basic framework to be able to run the workflow manually (workflow_dispatch), schedule it (schedule: cron), and have the ability to edit our own code (permissions):
on:
schedule:
- cron: '0 8 * * *'
workflow_dispatch:
jobs:
metadata-update:
runs-on: ubuntu-latest
permissions:
contents: write
steps:
It won’t actually do anything yet, but it is now technically a functional job called metadata-update.
Further workflow setup
Now time to add some actually useful steps! Just underneath the code added in the previous section, we need to add 3 steps:
1: Checkout a few files we need with GitHub’s actions/checkout10. For this repo sparse-checkout11 doesn’t save much time, but on a large repo it would help massively.
- name: Checkout channel config file
uses: actions/[email protected]
with:
sparse-checkout: |
automation/*
README.md
sparse-checkout-cone-mode: false
2: Run our script (./automation/youtube.sh) to perform all our tasks. We do chmod +x beforehand so we can execute the script, and configure both the API_KEY and WORKSPACE so our script has access to them.
- name: Update YouTube data
run: |
chmod +x ./automation/youtube-update.sh
./automation/youtube-update.sh
env:
API_KEY: ${{ secrets.API_KEY }}
WORKSPACE: ${{ github.workspace }}
3: Save the changes to the fetched metadata (stored in README.md) using git-auto-commit-action12. Note that I have intentionally configured the commit_author to not be me, by default it will use whoever triggered the workflow.
- name: Save changes
uses: stefanzweifel/git-auto-commit-action@v4
with:
commit_message: Updated YouTube statistics
commit_author: GitHub Actions <[email protected]>
file_pattern: 'README.md'
Once we put all those parts together, we end up with a functional metadata-update.yml file.
Bash script
As a reminder, our script will convert a list of channels into a table of channels with metadata. It will also allow displaying an arbitrary emoji (e.g. for “best” channels).
For example, our input of:
#### Stream Archives
UC2oWuUSd3t3t5O3Vxp4lgAA;2018-streams;🐶
UC4ik7iSQI1DZVqL18t-Tffw;2016-2018streams
UCjyrSUk-1AGjALTcWneRaeA;2016-2017streams
should result in an output of:
#### Stream Archives
| Channel | # Videos | Subscribers | Views |
| --- | --- | --- | --- |
| 🐶[Jerma Stream Archive](https://youtube.com/@jermastreamarchive) | 770 | 274K | 88M |
| [Ster/Jerma Stream Archive](https://youtube.com/@sterjermastreamarchive) | 972 | 47K | 20M |
| [starkiller201096x](https://youtube.com/@starkiller201096x) | 79 | 2.9K | 1.5M |
Creating script file
First, we need to make a bash file to actually run! Create your .sh file wherever you defined in step 2 above, I chose /automation/youtube-update.sh.
Parsing channel list
We have a plain text list of channels (channels.txt), with 2 types of data:
- Headers, in plain Markdown format (e.g.
### Title). - Channels, in the format
channel ID;nickname;emoji, where emoji is optional.
Reading the file is basically just “while there are lines left, parse them”:
HEADER_PREFIX="#### "
OUTPUT=""
while read -r LINE; do
if [[ ${LINE} == ${HEADER_PREFIX}* ]]; then
echo "Adding header ${LINE}"
OUTPUT="${OUTPUT}\n${LINE}\n\n"
OUTPUT="${OUTPUT}| Channel | # Videos | Subscribers | Views |\n| --- | --- | --- | --- |\n"
else
# Skipped for now
fi
done < "${WORKSPACE}/automation/channels.txt"
We’re finding header lines by just looking if they start with our HEADER_PREFIX string. If they are, we output the header, then create a Markdown table header, ready to populate with rows (1 per channel).
Note that OUTPUT is a constantly added to variable used to store the full Markdown data.
Calling YouTube API
Inside the else branch above, we first need to split our semicolon separated LINE into an ARRAY_LINE array of 2-3 items (due to optional emoji):
IFS=';' read -r -a ARRAY_LINE <<< "${LINE}"
Next, we output the channel ID ([0]) and nickname ([1]) to our logs, and use the ID (along with our API key from earlier) to call YouTube’s channel API and save the results to output.json:
echo "Adding channel ${ARRAY_LINE[1]} (${ARRAY_LINE[0]})"
curl "https://youtube.googleapis.com/youtube/v3/channels?part=statistics,snippet&id=${ARRAY_LINE[0]}&key=${API_KEY}" \
--header 'Accept: application/json' \
-fsSL -o output.json
Luckily YouTube’s channels API13 is very well documented and easy to use, and -fsSL is just a helpful curl config. We’re going to be fetching the statistics and snippet parts of the API, which will return JSON containing these key fields (irrelevant ones omitted):
{
"pageInfo": {
"totalResults": 1
},
"items": [
{
"snippet": {
"title": "Google for Developers",
"customUrl": "@googledevelopers"
},
"statistics": {
"viewCount": "234466180",
"subscriberCount": "2300000",
"videoCount": "5807"
}
}
]
}
Parsing JSON
Now that our useful data has been saved to output.json, we need to make it useful and parse it!
First, I make sure we have exactly 1 response by looking for the totalResults. If any error or unexpected behaviour is encountered, this is where it will be caught:
if [[ $(jq -r '.pageInfo.totalResults' output.json) == 1 ]]; then
# Skipped for now, see next code block!
else
echo "Failed! Bad response received: $(<output.json)"
exit 1
fi
If a single channel is returned, then we can pull out the useful data from output.json using jq14 and prepare our Markdown table row:
TITLE=$(jq -r '.items[0].snippet.title' output.json)
URL=$(jq -r '.items[0].snippet.customUrl' output.json)
VIDEO_COUNT=$(jq -r '.items[0].statistics.videoCount' output.json | numfmt --to=si)
SUBSCRIBER_COUNT=$(jq -r '.items[0].statistics.subscriberCount' output.json | numfmt --to=si)
VIEW_COUNT=$(jq -r '.items[0].statistics.viewCount' output.json | numfmt --to=si)
echo "Added ${TITLE}: ${VIDEO_COUNT} videos (${VIEW_COUNT} views)"
OUTPUT="${OUTPUT}| ${ARRAY_LINE[2]}[${TITLE}](https://youtube.com/${URL}) | ${VIDEO_COUNT} | ${SUBSCRIBER_COUNT} | ${VIEW_COUNT} |\n"
Some of these outputs (e.g. VIEW_COUNT) are then passed to numfmt15 to make them “pretty” (e.g. 2400 -> 2.4K). All the values are then used to build a self-explanatory row of data in Markdown format.
Note that currently the script inefficiently parses the JSON 5x. I intend to improve this, but as this script is very short and rarely run it is not urgent.
Saving data
Okay! So OUTPUT now contains lots of headers, and Markdown tables with lots of statistics. How do we do something useful with this?
I chose to use a placeholder file (with dynamic-channel-data being replaced by the list of channels), with the output replacing the repository’s README.md. This is surprisingly easy in bash:
# Replace placeholder in template with output, updating the README
TEMPLATE_CONTENTS=$(<"${WORKSPACE}/automation/template.md")
echo -e "${TEMPLATE_CONTENTS//${PLACEHOLDER_TEXT}/${OUTPUT}}" > "${WORKSPACE}/README.md"
# Debug
cat "${WORKSPACE}/README.md"
All we’re doing is loading up the template ($(<file)), replacing PLACEHOLDER_TEXT with our OUTPUT, and sending the output to README.md. Finally, the script outputs the contents of README.md so that there’s a copy in the logs.
Putting it all together
All done! Here’s the final script, with API_KEY and WORKSPACE being environment variables:
#!/bin/bash
HEADER_PREFIX="#### "
PLACEHOLDER_TEXT="dynamic-channel-data"
OUTPUT=""
# Convert list of channels into Markdown tables
while read -r LINE; do
if [[ ${LINE} == ${HEADER_PREFIX}* ]]; then
echo "Adding header ${LINE}"
OUTPUT="${OUTPUT}\n${LINE}\n\n"
OUTPUT="${OUTPUT}| Channel | # Videos | Subscribers | Views |\n| --- | --- | --- | --- |\n"
else
IFS=';' read -r -a ARRAY_LINE <<< "${LINE}" # Split line by semi-colon
echo "Adding channel ${ARRAY_LINE[1]} (${ARRAY_LINE[0]})"
curl "https://youtube.googleapis.com/youtube/v3/channels?part=statistics,snippet&id=${ARRAY_LINE[0]}&key=${API_KEY}" \
--header 'Accept: application/json' \
-fsSL -o output.json
# Pull channel data out of response if possible
if [[ $(jq -r '.pageInfo.totalResults' output.json) == 1 ]]; then
TITLE=$(jq -r '.items[0].snippet.title' output.json)
URL=$(jq -r '.items[0].snippet.customUrl' output.json)
VIDEO_COUNT=$(jq -r '.items[0].statistics.videoCount' output.json | numfmt --to=si)
SUBSCRIBER_COUNT=$(jq -r '.items[0].statistics.subscriberCount' output.json | numfmt --to=si)
VIEW_COUNT=$(jq -r '.items[0].statistics.viewCount' output.json | numfmt --to=si)
echo "Added ${TITLE}: ${VIDEO_COUNT} videos (${VIEW_COUNT} views)"
OUTPUT="${OUTPUT}| ${ARRAY_LINE[2]}[${TITLE}](https://youtube.com/${URL}) | ${VIDEO_COUNT} | ${SUBSCRIBER_COUNT} | ${VIEW_COUNT} |\n"
else
echo "Failed! Bad response received: $(<output.json)"
exit 1
fi
fi
done < "${WORKSPACE}/automation/channels.txt"
# Replace placeholder in template with output, updating the README
TEMPLATE_CONTENTS=$(<"${WORKSPACE}/automation/template.md")
echo -e "${TEMPLATE_CONTENTS//${PLACEHOLDER_TEXT}/${OUTPUT}}" > "${WORKSPACE}/README.md"
# Debug
cat "${WORKSPACE}/README.md"
Lessons learned
Bash
My bash / shell knowledge is pretty weak. I don’t write any local automation / scripts, and only interact with it for CI things like this, so I’ve always found it painful and unintuitive to work with.
However, making a useful script like this has definitely made me appreciate how easy it makes tasks that would be awful in other languages. For example, loading the contents of a file into a variable is just… $(<file). Sure, I bet it doesn’t work perfectly for all situations, but realistically when programming you usually just want super simple “default” syntax.
I also really appreciated how easy it was to pass data between utilities, and how useful these utilities could be. When I wanted to make numbers human-readable (e.g. “2.5M”), I initially got lost in a rabbit hole of writing a helper function, doing string manipulation, etc. Then, by sheer chance, this Stack Exchange question came up mentioning “convert … to human-readable”, and I discovered numfmt exists! It does exactly what I want, is built-in, yet none of the 10+ answers about number formatting mentioned it whatsoever.
I can’t entirely explain why it took so long for me to find numfmt. Perhaps the primary fault is with me assuming I’d have to solve it myself, so looking for manual solutions instead. However, a large part of the issue is with every bash related answer either:
- Saying “use x”, with either no extra information, or an extensive argument in comments about why other options were better.
- Giving a comprehensive “use x if y, or z if a, but only use b if cde is true” style answer. For example, this semi-related answer actually included the
numfmtinformation I wanted, but it was so lengthy and caveat-filled that I just didn’t read it.
Shellcheck
Shellcheck exists! It’s a super simple utility available as a website or package that tells you why your code sucks, basically providing linting. This helped me make a few simple improvements to my script around string escaping, and provided justifications for everything (e.g. why ${OUTPUT} is significantly better than OUTPUT).
YouTube API quirk
Whilst YouTube’s Channel API13 is great, as is the ability to make test calls in the browser, it has a weird quirk. Searching by username… doesn’t seem to work half the time? I’m not sure if this is due to channel size or something else, but around 50% of the channel names simply returned 0 results. The documentation provides no explanation for this, just:
The
forUsernameparameter specifies a YouTube username, thereby requesting the channel associated with that username.
Luckily, searching by id worked perfectly, and has the added benefit of never changing. It could also (one day) be used to look up multiple channels at once:
The
idparameter specifies a comma-separated list of the YouTube channel ID(s) for the resource(s) that are being retrieved. In a channel resource, theid` property specifies the channel’s YouTube channel ID.
Quotas
GitHub Actions and YouTube have generous free quotas!
Whilst I do have a GitHub Pro plan, the CI time per month is only 3,000 vs 2,000 for a free plan16. Since the script takes under a minute for the current channel list, and runs once a day, we’re using ~1% of the free quota. Oddly enough, my usage statement17 (even the raw downloadable CSV) shows 0 minutes used so far this month, not sure why:

For YouTube, you can make 10k requests per day for free. Considering each channel lookup only counts as 1, this is way more than we need! This opens up the possibility of fetching the latest / most popular video for each channel in the future.

Error handling
Currently, my script has basically no error handling, and if anything goes wrong just throws an error and gives up.
Whilst this might seem like a flaw, it’s by design. As a failed run doesn’t make the data any less valid, just slightly out of date, that is massively preferable to a corrupted run with invalid outputs. Additionally, I automatically a recieve an email on failed builds, so I can just rely on this to let me know if any channels have been deleted or other errors have occurred.
Conclusion
In conclusion, this was a very fun mini project! I learned a lot about GitHub Actions and Bash, both of which I wanted to get better at.
Whilst the actual project is obviously a little silly, I like the idea of turning random hobbies into useful tools for others. This also gives me an automated tool that I can use if I want to try GitHub Actions features in the future, and has plenty of additional functionality that could be implemented.
I was pretty impressed with how simple GitHub Actions was to use, with even spurious ideas (“hey can I only fetch the required files?”) being well documented and easy to implement. The “auto-commit” library was also impressive (and seems well maintained), with default functionality working exactly as expected, yet also having the ability to customise it to my requirements.
Finally, this writing up of how the script works is mostly to remind myself about bash. I know when I try and do something else CI-related in 6 months I’ll be confused by the syntax, so hopefully this post will remind me that I briefly understood it once!
One last time, the results of this article are available at channels.jerma.io.
References
-
https://console.cloud.google.com/apis/library/youtubeanalytics.googleapis.com ↩
-
https://cloud.google.com/docs/authentication/api-keys#api_key_restrictions ↩
-
https://docs.github.com/en/get-started/quickstart/create-a-repo ↩
-
https://developers.google.com/youtube/v3/docs/channels/list ↩ ↩2
-
https://www.gnu.org/software/coreutils/manual/html_node/numfmt-invocation.html ↩
-
https://docs.github.com/en/billing/managing-billing-for-github-actions/about-billing-for-github-actions#included-storage-and-minutes ↩