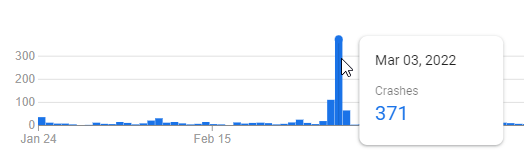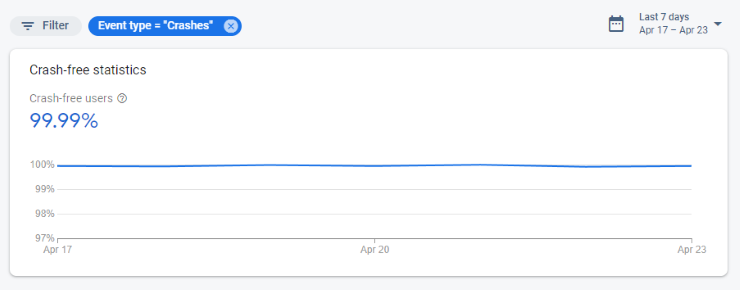
From 99% to 99.99%, why & how to chase 100% Crashlytics crash-free users
In services with uptime, availability is often measured in the number of 9s, e.g. “4 9s” is 99.99% uptime. Whilst installed apps themselves don’t tend to have uptime in the same way, they do have another critically important metric: % of crash-free users! I’ve always heavily focused on this metric, so here’s some of the things I’ve picked up whilst chasing 100%.
For context (and, okay, a little brag), I led the Android app of ITV Hub from 98.2% -> 99.7% crash-free users, and Photobox from 99.10% to ~99.98%.
What is “crash-free users” measuring?
First of all, what are crash-free users? Well, it’s an aggregation over time of how many of your users in a given time frame experienced a crash. The Firebase docs go into this in a bit more detail, but essentially if 1000 people use your app in a day, and 10 of them experience a crash, you have 99.9% crash-free users.
The impact of this obviously depends on the size of your userbase. For some of my smaller apps, having 90% crash-free users is fine, as it’s only 1-2 people experiencing crashes. For something like ITV Hub, this would be tens of thousands of people!
Why improve crash-free users percentage?
So, who cares? Crashes happen, right?
In larger companies, most aspects of an app will be monitored and improved by product / design / marketing / engineering employees. Whether this is the impact of an email campaign, A/B testing a screen design, or customer-exclusive discounts, these all take significant effort to introduce a minor uplift in sales / users. Crashes however, skip this process entirely, yet may be causing more attrition than anything else combined!
From my experience, this is because engineering alone are generally responsible for the crash-free rate, whilst all other initiatives have design and product input. This leads to a lack of visibility, and ultimately no incentive to actually improve the metric unless an engineer champions it…. like I am now.
Reflects a real problem for real people
First and foremost, this isn’t a metric like conversion rate tracking how many users had a positive interaction. Instead, it is tracking how many had a catastrophic experience.
Depending on when and how an app crashes, it might be barely noticeable (e.g. this crash when a user unlocked their phone whilst Chromecasting) or be completely catastrophic (e.g. a crash on app startup I recently introduced (and fixed!)). Each of those crashes can very easily be a permanently lost user, who might leave a negative review and tell their friends how awful the app is, leading to a single programming typo causing thousands in lost revenue. Not great.
Crashes beget crashes
So, let’s say your app crashes when the user opens it at exactly midnight on February 29th. Pretty edge case, so it’s fine to just leave it, right?
Nope! When your app crashes, it can permanently damage the installation. For example, if it crashes halfway through a bulk database update, the database could become corrupted, or even worse only partially updated. This could then cause seemingly impossible data mismatch issues days or weeks later, wasting hours of time for the user, customer service, and developer.
If the crash had been fixed as soon as it was noticed, and safety checks for any affected user data implemented, this could have been avoided weeks ago.
Investigations can reveal underlying / upcoming issues
Crashes don’t come out of nowhere (well, almost never). Instead they are a symptom of programming issues, from accidentally trusting a variable to be non-nullable to assuming a device will always have a certain characteristic (especially prevalent on Android devices, some of which defy all expectations!).
As such, during the investigation into a crash the root cause is often a future problem lying in wait. I previously experienced a rare crash around device Widevine DRM capabilities. We ignored it as it was only occurring on “Android TV boxes”, the sometimes legally shady devices that aren’t certified to playback encrypted content. A few weeks later however, we discovered a newly released OnePlus phone had somehow yet to gain the certification, so would crash too!
The “fix” was to check the DRM was supported (despite all normal phones & tablets having it), and trying to help the user understand what was wrong by showing an error message. This approach helps users find a solution themselves, and is a memorable example where I ignored a crash due to the unconventional device and regretted it.
Easily understandable metric
When expressing the need for tech debt reduction work, most engineering reasons realistically will have little impact on non-engineers as they’re not measurable. “The codebase sucks” is an awful argument, “500 users a day are experiencing crashes in our photo editor” is excellent. Crash-free users works as both an indicator of the app’s current state, as well as a tool to measure the impact of any changes, free from metrics such as conversion that are easily contaminated by other initiatives.
Selfishly, “improved crash-free users from 99.7% to 99.95%” is also an excellent thing to see on a CV! It implies the engineer cares about real users, understands their work is not just code, whilst also being an easy metric to talk about and share with outsiders.
Amazing effort to reward ratio
Finally, crash fixing (at least on Android) is often pretty easy. There are absolutely times when a single crash can take weeks, but in my experience almost all crashes are easy fixes. Maybe a value is unexpectedly null, maybe a variable can take longer than expected to initialise, issues like this can often take longer to write the PR than fix.
Because of this, a few hours a week of my time has significantly improved the app experience for tens or hundreds of thousands of users. It’s somewhat sobering to consider that my almost hobbyist crash fixing could easily have made my employers more money than any major new feature / improvement I’ve actively developed!
How to improve crash-free users percentage?
Alright, so hopefully at least one of the points above has convinced you that the crash-free users % at least needs to be looked at occasionally, and improved if possible.
So… how?
Have the information you need, and use your tools
You can’t fix a crash if you can’t see what’s going on. Most apps have far too many various tracking solutions already in place, and they’re probably good enough if used properly.
I’ve always used Crashlytics, and it actually has a custom logging feature built in. However, it becomes drastically more powerful when your app also uses Google Analytics (GA), which most do. The GA events are automatically connected to the crash, meaning you get a detailed history of the user’s actions before the crash.
This is unbelievably helpful when tracking down a rare crash, especially when combined with custom user keys and event parameters. For an example, here’s a recent crash’s stack trace:
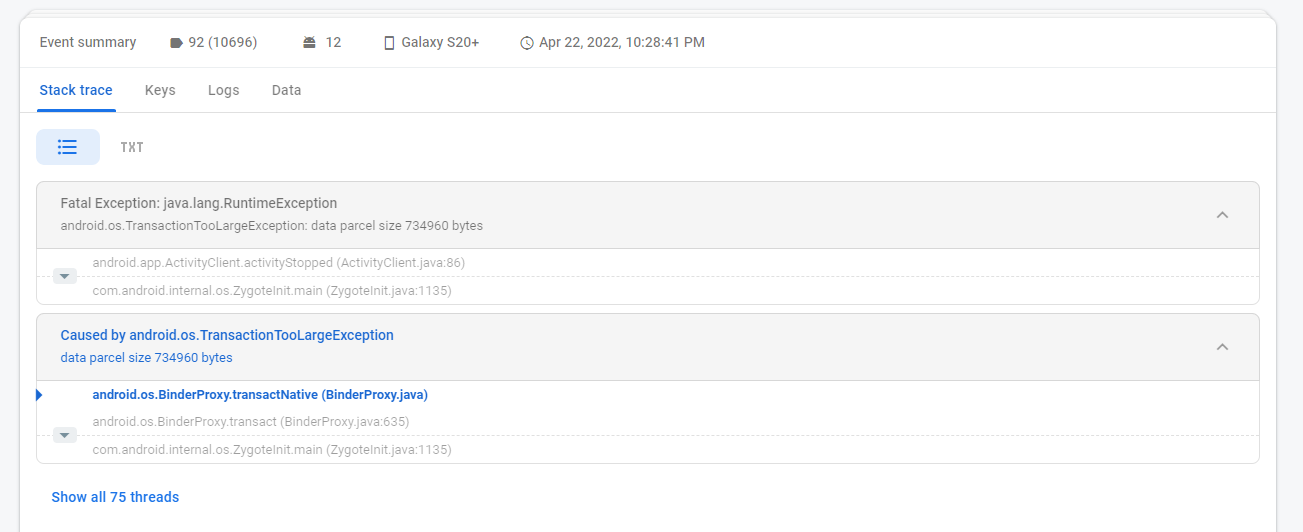
Our app’s code isn’t even mentioned here! A transaction, somewhere, is too large. Unsolveable, right? Well, let’s take a look at the logs:
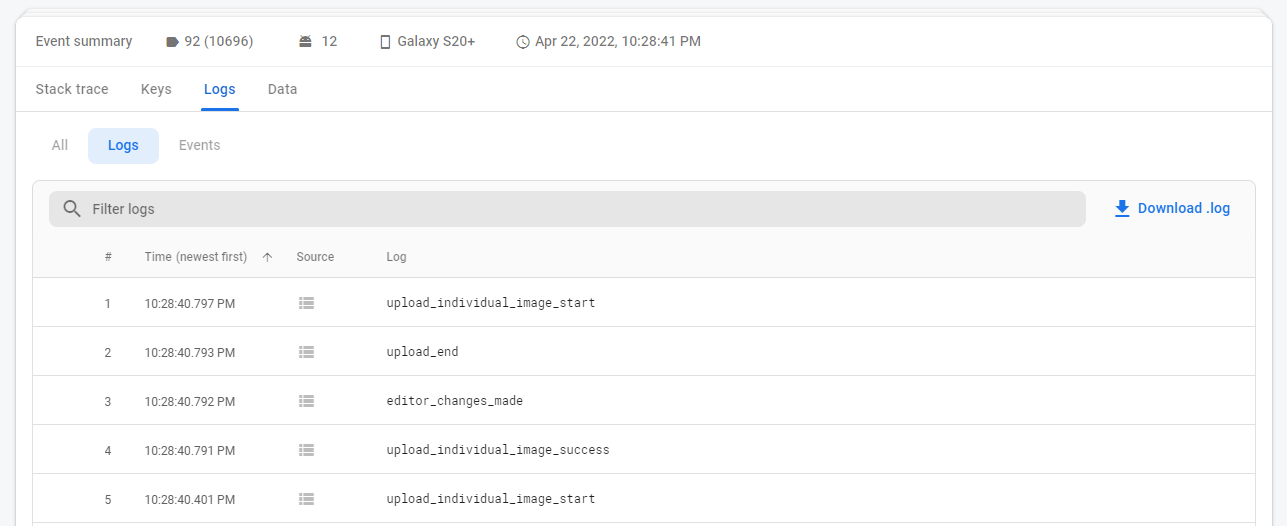
Ah! The user is uploading photos! Alright, now we know the screen and actions taken, so have a starting point. However, we test upload pretty often, how come we haven’t experienced this ourselves? Maybe there’s a clue in the user keys…
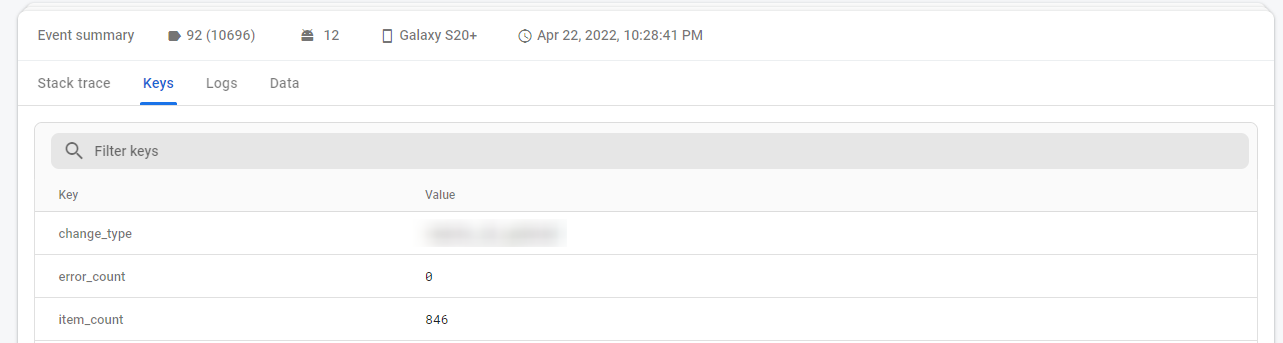
Well, we don’t test uploading 846 images that often. From this, we can pretty reliably conclude that inside our image uploader we are using too much metadata per image, leading to crashes on high image counts when passing this data around. Without looking at a single line of code, we’ve identified a likely cause and fix for a crash!
Build a routine
Personally, I don’t think having a “crash fixing week” or similar is super beneficial. Crashes are constantly being introduced into an app and accumulate, so fixing as many as possible every few months means easily fixable crashes spend weeks in the wild.
Instead, fix crashes little and often. At Photobox, we use approximately weekly releases. I use Crashlytics to monitor the latest release, and will try to fix the top 2-3 crashes for the next week’s release. This way, any newly introduced crashes are fixed, and historical ones eventually are too.
Additionally, by constantly maintaining the crash rate, any crashes caused by a new architecture / approach / library can be quickly fixed before the use of it spreads further in the codebase.
Monitor monitor monitor
You can’t improve crash rate if you aren’t looking at crashes! Firebase has various options for integrating with Slack, Jira, PagerDuty, and email, make sure you’re at least keeping an eye on high velocity crashes.
I also have a Crashlytics tab filtered to the latest release pinned on Chrome, and quickly check it each morning to make sure we’re still at 99.9%+ crash-free. Only takes a second, and has caught a few issues before they’ve escalated.
Take code quality seriously
Approximately a million posts have been written about programming styles, architectures, paradigms etc, so I won’t cover any of those! Instead, I’ll just say tools like lint & detekt and decent PR processes exist for a reason. Use them.
The only crash that doesn’t impact your crash-free percentage is one that never makes it to real users.
Publicise your number
Perhaps most importantly, take pride in your crash-free rate! Whilst sales, conversions, and even store rating may be monitored and bragged about in Slack and all-hands presentations, crash rate rarely gets mentioned. By making it a public statistic, there’ll be an extra incentive to maintain it, as well as allowing everyone to be aware of the current app stability.
At Photobox a colleague posts weekly about the crash rate (and other key metrics) in an app team internal channel, allowing non-engineers to keep an eye on it. Whilst realistically these numbers are pretty similar week to week, it’s a great way to make sure the number doesn’t slip.
The crash rate is also mentioned when it hits a new milestone in wider meetings with hundreds of people, and should absolutely be celebrated as much as a new product launch (so long as it isn’t a temporary boost!). We celebrated when we hit our first 100% crash-free day, although I’m fully aware that’s not possible when working on a larger app, and is somewhat luck-based.
Be realistic
Finally, accept that you won’t consistently reach 100% crash-free users. On smaller apps you may hit this occasionally, but hitting it for longer periods is impossible. In decreasing order of likelihood, this is due to:
- Continued development introducing new crashes.
- The sheer variety of Android hardware and software causing a single unheard-of manufacturer’s devices to crash when running your app.
- Crashes caused by third party libraries.
- Crashes caused by the user interfering with your app via storage editors.
- Crashes caused by the device itself being unstable, e.g. battery removed, SD card removed, storage wiped.
Because of this, “4 9s” is the most you can hope to achieve, and coincidentally is the maximum level of detail shown in Crashlytics. If you’re seeing all 9s, your app is phenomenally stable!
Conclusion
In conclusion, time to take a cold hard look at your app’s crash rate!
Hopefully this post has convinced you how vital a metric crash rate is, as well as providing you with the techniques and tools to make it a metric to be proud of.
Oh, and remember every app has a bad day…