How to bulk download all past versions of a webpage, parse the data in Python, and save to CSV
I recently needed to download hundreds of past versions of a StumbleUpon webpage, parse the HTML, and output the data into a CSV for further analysis. Here’s how to do it!
What’s the goal?
For an upcoming project, I needed to extract as much historical data (2009-2012) from StumbleUpon as possible, and output it into a CSV. The obvious approach to this is using Archive.org’s Wayback Machine to download all versions of “top posts” pages, then some Python processing to extract data from the downloaded pages.
To summarise, my input is a target URL, my desired output is a CSV with information extracted from the multiple results contained within each historical version of the URL’s contents.
If you just want to see the code, here’s a GitHub gist of the Python scripts & batch command, plus a full GitHub repo including results.
What’s the plan?
Assuming I already have a URL I wish to extract from, my plan is:
- Step 1: Download every version of the URL available.
- Step 2: Parse the downloaded pages into a CSV.
- Step 3: Tidy up the resulting data.
Step 0: Prepare environment
We’re going to be using Python to download the pages and parse the downloaded data, so first we need a decent environment for it!
You can of course skip the Python installing step if you already have it configured, you will however need to install the libraries this guide uses.
Installing Python
I installed it on my Windows machine without any problems, but make sure to follow any platform-specific instructions.
- Download the latest version from Python.org.
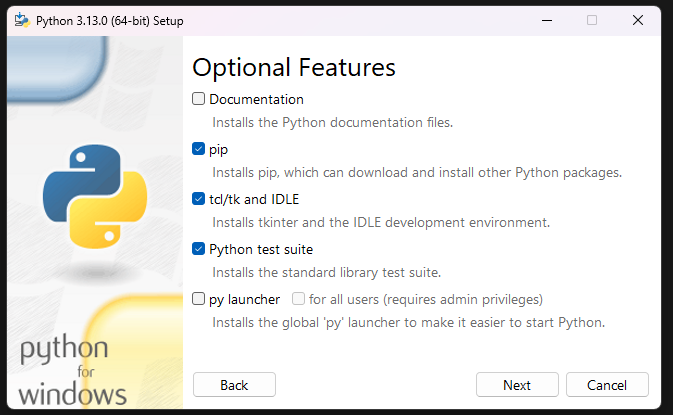
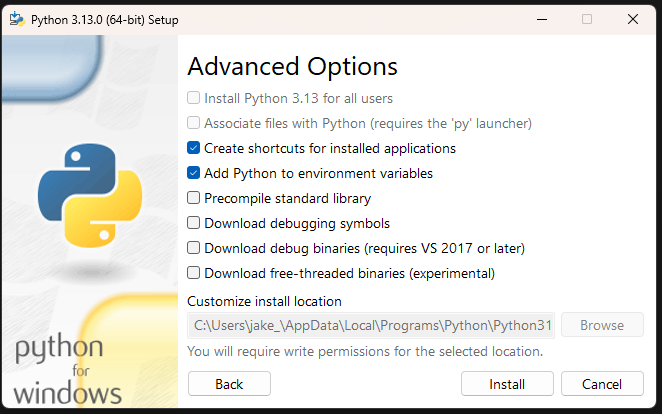
- Install with mostly default options, plus:
- The “Optional feature”
pip(to install packages). - The “Advanced option”
Add Python to environment variables(to allow command line usage).
- The “Optional feature”
I initially installed Python without either of these features, and had to rerun the installer and select “Modify”. Oops.
| Optional features | Advanced options |
|---|---|
 |
 |
Installing libraries
We’re going to be using 4 libraries for this project:
waybackpack: To automate the Wayback Machine downloading process.beautifulsoup4: To parse & extract data from the downloaded HTML.lxml: Adds a (generally) faster parser thatbeautifulsoup4can use (more info).pandas: To deduplicate the CSV output.
Luckily, we can install all of these at once in a single command in Command Prompt:
pip install waybackpack beautifulsoup4 lxml pandas
After a few minutes of installing, we’re ready to go!
Step 1: Downloading all versions
As mentioned, we’ll be using waybackpack to download every version of our target URL(s).
Preparing download script
Whilst the most basic usage is just waybackpack {url} -d {destination}, There’s quite a few config options available for this utility that drastically improve behaviour. Here’s what I ended up with:
waybackpack ^
http://www.stumbleupon.com/discover/toprated/ ^
-d "/Projects/StumbleUpon-extract/data-raw" ^
--from-date 20091001 ^
--to-date 20120318 ^
--raw ^
--no-clobber ^
--delay-retry 2 ^
--max-retries 10 ^
--ignore-errors ^
--user-agent "waybackpack {myemail}"
So, what does it all do?
- The
^at the end of each line lets me copy & paste into the command prompt as a multi-line command for ease of reading. from-dateandto-dateneed customising based on your URL. For my target URL, I noticed the valid archives are only between October 2009 and March 2012, after which all the requests fail. Adding these fields avoids pointlessly fetching a few years worth of error / redirect pages!rawfetches the actual source content, without the Wayback Machine URL rewriting, added JavaScript, or any other changes. This is useful since we want the original data, not to actually browse the pages.no-clobberskips trying to fetch any files that are already downloaded. This ensures running the same command again will only try to fetch the failed pages, not all the successful ones.delay-retryandmax-retrieshandle the retry delay (in seconds) and how many tries to make before giving up. Archive.org was fairly unreliable at time of writing, so connection errors were quite common. Running the entire command again a few minutes later typically resolved the problem.- Whilst network / server errors are handled already,
ignore-errorsensures errors within the code don’t stop the whole extract process. user-agentcontains the tool we’re using, and my email, as a courtesy to Wayback Machine in case the tool is doing something wrong with their API, or they need to contact me.
Running download script
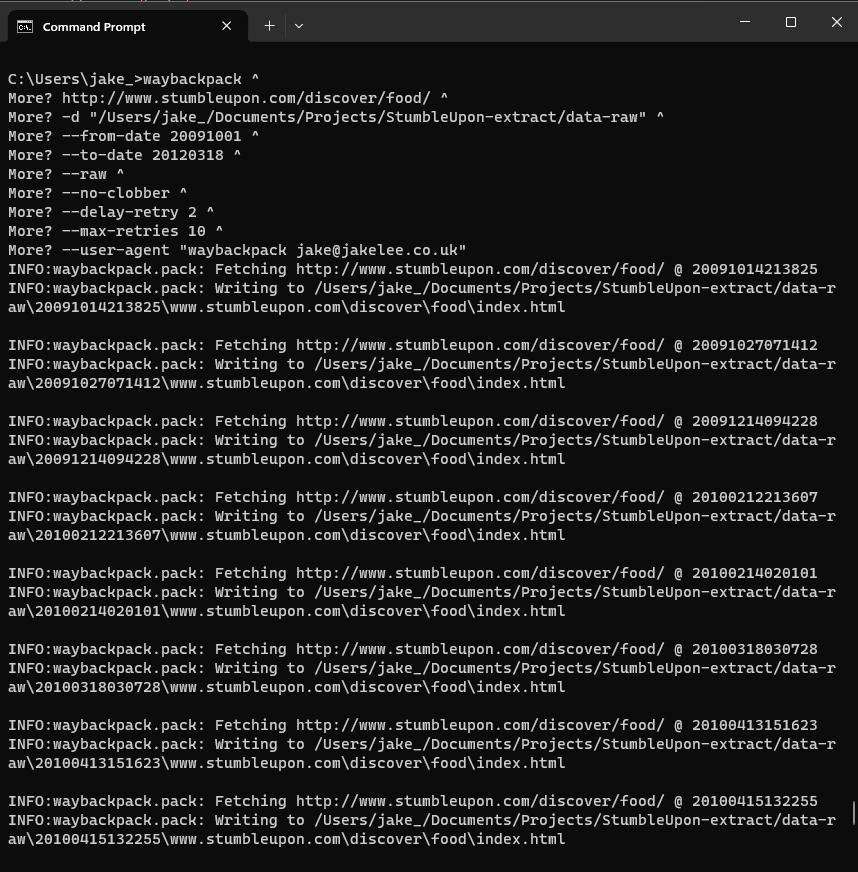
Copying and pasting the whole command into Command Prompt will start the download process, with each archive taking under 1 second for successful fetches, and up to 20 seconds for unsuccessful fetches. Total time is typically 3-4 seconds per copy.
Notes:
- The files will end up in the specified destination in the format
/timestamp/url, creating any necessary folders. For example,http://www.stumbleupon.com/discover/toprated/will be saved in/20120101165409/www.stumbleupon.com/discover/toprated/index.html. - Passing a URL ending in
/will result inindex.html, otherwise the filename will be the path (e.g.topratedwith no extension). - It’s likely a few fetches will fail (with max retries) on first attempt, so I’d recommend running the command a couple more times until the only failures are
HTTP status code: 301. Each retry should try fewer and fewer URLs due to theno-clobberoption!
| Example output | Poor connection output | Downloaded files |
|---|---|---|
 |
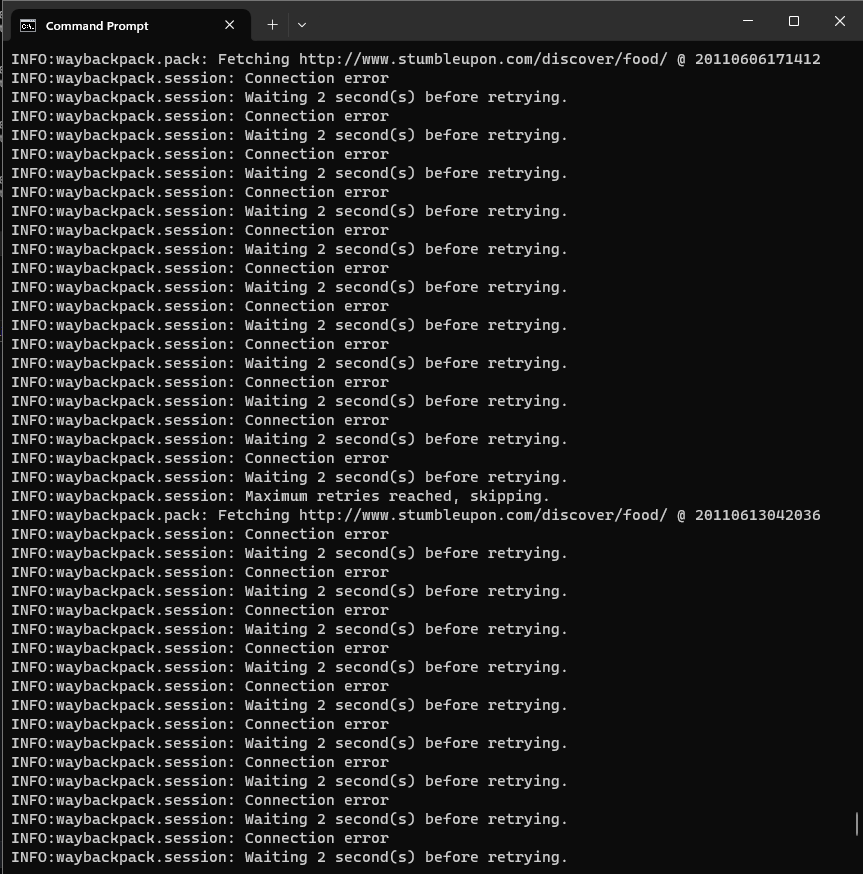 |
 |
Step 2: Parsing data into CSV
This step is going to be relatively specific to my use case; extracting links from archived StumbleUpon pages. However, the overall approach is applicable to any data extracting needs, with just the specific fields needing changes.
Requirements
For my scenario, the requirements were:
- Parse each downloaded HTML file, and extract the 10 links included.
- For each link, extract as much metadata as possible (e.g. views, title, URL).
- Output the extracted metadata into a CSV for further analysis.
- Automate the process as much as possible!
Before diving into the solution, it might be helpful to look at sample inputs and outputs to clarify the objectives:
- Sample input HTML, containing 10x links (sample) plus lots of irrelevant data.
- Sample output in CSV format (note GitHub will autoformat into a table for readability).
We’ll run our script with python extract_stumbleupon_metadata.py, which will extract all the metadata from each file:
PS C:\Users\jake_\Documents\Projects\StumbleUpon-extract> python .\extract_stumbleupon_metadata.py
2024-10-19 22:24:47: Processed 10 items from #1: data-raw\20091010195948\www.stumbleupon.com\discover\bizarre\index.html
2024-10-19 22:24:47: Processed 10 items from #2: data-raw\20091010200605\www.stumbleupon.com\discover\toprated\index.html
2024-10-19 22:24:47: Processed 10 items from #3: data-raw\20091011005504\www.stumbleupon.com\discover\health\index.html
2024-10-19 22:24:47: Processed 10 items from #4: data-raw\20091011005516\www.stumbleupon.com\discover\movies\index.html
2024-10-19 22:24:47: Processed 10 items from #5: data-raw\20091011005527\www.stumbleupon.com\discover\travel\index.html
2024-10-19 22:24:47: Processed 10 items from #6: data-raw\20091011105316\www.stumbleupon.com\discover\news\index.html
Script overview
The Python script is on GitHub, although it’s a little messy as it’s specific to this project!
Before diving too deep into a line-by-line analysis, here’s how the script works:
- Step 2a: Define a few parameters around input and output, and check the local environment.
- Step 2b: Define a
extract_metadatafunction that opens the HTML file passed to it, parses all the links, and returns a list of metadata objects (each of which is a CSV line). - Step 2c: Find every downloaded HTML file, pass them to
extract_metadata, and save all the metadata into theoutput_csv.
Step 2a: Overall setup
Tiny bit of simple setup, before the useful functionality starts:
- The
root_dirandoutput_csvvariables let the script know where the HTML input files and CSV output file should be. max_filesis used to aid testing, to try parsing 1-2 files initially.stumbleupon_prefixis used for extracting the “real” URLs.- Finally,
os.makedirsensures the output CSV folder exists and is accessible.
import os
import csv
from bs4 import BeautifulSoup
from datetime import datetime
from urllib.parse import unquote
root_dir = r'data-raw'
max_files = 10
stumbleupon_prefix = 'http://www.stumbleupon.com/url/'
output_csv = 'data-parsed/parsed.csv'
os.makedirs(os.path.dirname(output_csv), exist_ok=True)
Step 2b: Metadata extracting
Whilst there’s quite a big chunk of code inside extract_metadata, none of it is actually very complicated or clever!
All we’re doing is finding every listLi element, pulling out data within it, and adding it all to our metadata dictionary. These are then all collated and returned to the caller. The desired output is similar to:
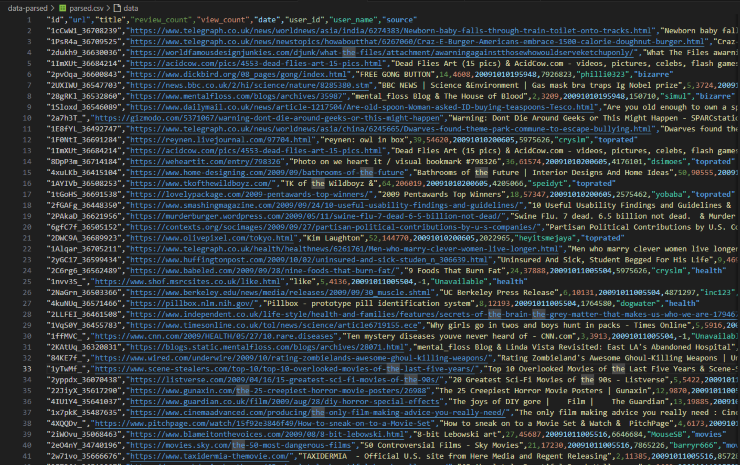
"id","url","title","review_count","view_count","date","user_id","user_name","source"
"1x8XK0","https://www.typographyserved.com/Gallery/August-2009/282018","August 2009 :: Typography Served",14,24224,20091011113141,2342625,"Lyze","toprated"
"2PAkaD","https://murderburger.wordpress.com/2009/05/11/swine-flu-7-dead-6-5-billion-not-dead/","Swine Flu. 7 dead. 6.5 billion not dead. & Murder Burger et al.",33,40291,20091011113141,7259679,"growmap","toprated"
And the Python function to do this is:
def extract_metadata(file_path):
with open(file_path, 'r', encoding='utf-8', errors='ignore') as file:
content = file.read()
soup = BeautifulSoup(content, 'lxml')
list_items = soup.find_all(class_='listLi')
metadata_list = []
for item in list_items:
user = item.find(class_='avatar')
reviews = item.find(class_='showReview') or item.find(class_='showStumble')
raw_url = f'https://{reviews.find("a")["href"][len(stumbleupon_prefix):]}'
views = item.find(class_='views')
# Assumes relative path `data-raw\20091011113141\www.stumbleupon.com\discover\toprated\index.html`
path_parts = file_path.split(os.sep)
metadata = {
'id': f"{item.find('var')['class'][0]}_{item.find('var')['id']}",
'url': unquote(unquote(raw_url)),
'title': item.find("span", class_='img').find("img")["alt"].strip(),
'review_count': int(''.join(filter(str.isdigit, reviews.find('a').get_text(strip=True).split()[0]))),
'view_count': int(''.join(filter(str.isdigit, views.find('a')['title'].split()[0]))),
'date': int(path_parts[-5]),
'user_id': int(user['id']) if user else -1,
'user_name': user['title'] if user else 'Unavailable',
'source': path_parts[-2]
}
metadata_list.append(metadata)
return metadata_list
Before looking at a detailed data extraction example, it’s worth highlighting that the downloaded data is a little unreliable / messy. As such, a few notes:
- The metadata
idis a combination of the post’s CSSclassand theid, since the class names aren’t necessarily unique, andidis sometimes missing. - Sometimes the
useris empty, so we need default values. - We double
unquotetheurlto get a “real” URL out. - Some pages have the URL as the title. This is not an error in the data, it’s on the site too (last result)!
Extraction step-by-step
The parsing can seem complicated, but they all just require careful reading. Looking at an example listLi element, we have this source HTML:
<p class="showReview">
<a
href="http://www.stumbleupon.com/url/sciencehax.com/2010/01/beautiful-home-built-from-recycled-materials/"
>46 reviews</a
>
</p>
We first need to actually find this element, it is usually the element with class showReview but can be showStumble in some scenarios. This can be expressed as:
item.find(class_='showReview') or item.find(class_='showStumble')
Now we have the reviews object, we can chain a few Python functions on it:
int(''.join(filter(str.isdigit, reviews.find('a').get_text(strip=True).split()[0])))
How does this work? Well, from the inside out:
- First we find the
aelement (reviews.find('a')) and get the link text (get_text), giving us46 reviews. - Next, we split this into
46andreviewsand take the first string (with.split()[0]). - Now, we make sure this is a simple number (e.g.
12,345to12345) by removing any non-numerical characters (filter(str.isdigit, "46")). - This gives us the array
["4", "6"], so we use''.jointo put it back into a single string. - Finally,
int()wraps everything, as we want a numerical output (to avoid any quotation marks in the CSV).
Hopefully that example highlights how seemingly complex parsing is pretty straightforward, even for other fields that are fetched from the file’s path itself (path_parts).
Step 2c: File input & output
As a reminder, our goal is to find every available .html or extensionless file, parse them with extract_metadata, then save the extracted data into a CSV.
We’ve got a bit of extra logic to output the CSV headers, and allow limiting the number of files to parse, as well as outputting timestamps for logging purposes.
with open(output_csv, 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = ['id', 'url', 'title', 'review_count', 'view_count', 'date', 'user_id', 'user_name', 'source']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames, quoting=csv.QUOTE_NONNUMERIC)
writer.writeheader()
# Traverse directories and process HTML files
file_count = 0
for subdir, _, files in os.walk(root_dir):
for file in files:
if file_count >= max_files:
break
file_path = os.path.join(subdir, file)
# Check if the file has no extension or has an .html extension
if not os.path.splitext(file)[1] or file.endswith('.html'):
metadata_list = extract_metadata(file_path)
for data in metadata_list:
writer.writerow(data)
file_count += 1
current_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print(f"{current_time}: Processed {len(metadata_list)} items from #{file_count}: {file_path}")
if file_count >= max_files:
break
Again, nothing complicated here, it’s just a big old nested for loop looking at every file in the input directory!
Step 3: Sanitising the data
Since we downloaded every toprated page version available on the Wayback Machine, some of the data will actually overlap! This page only updates slowly, so there’ll be a few overlapping items even with archives 24 hours apart.
Additionally, I actually downloaded content from /toprated/, /animation/, /arts/, totalling over 30 URLs (full list)! Downloading all copies of all these URLs resulted in 1,545 HTML files (/data-raw/), which contained a total of 13,365 items.
However, we know we have duplicates. This problem is made much worse when fetching data from category pages, since obviously popular content in a category will end up on the overall toprated screen. Uh oh.
Deduplication
Luckily, we used a sensible id earlier that doesn’t include anything date-related!
As such, we can just deduplicate our CSV by this ID. We should take the last instance of an ID, since all of our data is automatically date sorted (due to the download tool using date folders).
Using the data analysis tool pandas, we can create a tiny clean_stumbleupon_metadata.py that does exactly what we want:
import pandas as pd
import csv
df = pd.read_csv('data-parsed/parsed.csv')
df = df.drop_duplicates(subset='id', keep='last')
df.to_csv('data-parsed/parsed-cleaned.csv', index=False, quoting=csv.QUOTE_NONNUMERIC)
Running this creates a new, deduplicated parsed-cleaned.csv containing just 4,443 rows from the original 13,365. Perfect!
This data is also available as a Google Sheet.

Conclusion
So, to summarise what we’ve done, in terms of our original plan:
- Step 1: We ran
waybackpackwih our target URL, and ended up with hundreds ofhtmlfiles. - Step 2: Next, we ran our
extract_stumbleupon_metadata.pyscript, a few minutes later ending up with a CSV full of all extracted data. - Step 3: Finally, we ran
clean_stumbleupon_metadata.pyto remove duplicated data.
This approach can be adapted for use on any URL or data format, and whilst none of it is very complicated, it’s my first time doing anything notable in Python. Lots of things learned!
The final CSV will be used for an upcoming post on Internet History. Aaaand as one final reminder, all code and data from this article is available on GitHub.